Panoramic Case Study
About the Customer
Panoramic mission is to help our clients achieve their business objectives by providing them with tailored services that meet their specific needs. They strive to understand our clients’ goals and work closely with them to develop a customized digital marketing strategy that is designed to help them succeed.
At the Marketing Express, they have a team of highly skilled professionals who are passionate about helping clients achieve their goals. Their team members come from diverse backgrounds and have a wide range of expertise in areas such as SEO, social media marketing, email marketing, and more. Together, they work collaboratively to ensure that clients receive the best possible digital marketing services.
Business Challenges:
- Employees spent excessive time searching across documents and shared drives.
- Knowledge was siloed across departments with no unified search experience.
- Manual support requests increased operational overhead.
- Inconsistent answers due to outdated or duplicated documents.
Technical Challenges:
- Need for a secure GenAI solution that keeps sensitive data private.
- Requirement to avoid hallucinations by grounding AI responses in verified documents.
- Scalability to support concurrent users across departments.
- Seamless integration with existing document repositories.
- Need for auditability, logging, and compliance.
- Maintain strong security, logging, and auto-scaling through containerized backend services and CDN-backed frontend delivery.
Risks and Impact if the Challenge Were Not Addressed
Without an AI-powered knowledge assistant, Panoramic risked:
- Continued productivity loss due to inefficient information discovery.
- Higher dependency on SMEs and support teams.
- Poor onboarding experience for new employees.
- Limited ability to scale knowledge access across growing teams.
- Competitive disadvantage in adopting AI-driven enterprise workflows.
- AI capabilities (voice, multi-agent flows, self-service analytics) across future applications.
Partner Solution
To address these challenges, Panoramic implemented a Retrieval-Augmented Generation (RAG) platform on AWS, enabling employees to interact with organizational knowledge through a conversational AI interface.
The solution combines Amazon Bedrock (Claude 2) with Amazon OpenSearch and serverless AWS services to deliver accurate, context-aware answers grounded in enterprise documents.
Key Architecture Components
- Frontend Layer
- A static web interface hosted on Amazon S3 enables users to submit natural language queries.
- The UI communicates securely with the backend through Amazon API Gateway.
- API & Orchestration Layer
- Amazon API Gateway receives chat requests and routes them to the backend.
- AWS Lambda (RAG Logic) orchestrates:
- Query processing
- Embedding generation
- Vector search
- Prompt construction
- LLM invocation
Generative AI Layer
- Amazon Bedrock – Claude Haiku is used for:
- Natural language understanding
- Context-aware response generation
- Secure, managed LLM inference
- Vector Search & Knowledge Layer
-
- Amazon OpenSearch (Vector Index) stores embeddings of all documents.
- Enables fast semantic search to retrieve the most relevant document chunks for each query.
- Document Ingestion Pipeline
When a new document is uploaded:
-
- Document is stored in Amazon S3 (Knowledge Base bucket)
- A Lambda processor is triggered
- Text is chunked and converted into embeddings using Bedrock Embeddings
- Vectors are stored in Amazon OpenSearch
- Metadata is indexed for traceability and governance
Functional Workflow:
Step 1 – User Query
Employees submit questions such as:
-
-
- “What is our leave policy for remote employees?”
- “Explain the onboarding process for new hires.”
- “Where is the disaster recovery runbook?”
-
Step 2 – Query Understanding
The backend Lambda function:
-
-
- Converts the query into embeddings
- Performs a vector search in OpenSearch
- Retrieves the most relevant document chunks
-
Step 3 – Contextual AI Reasoning
-
-
- Retrieved content is passed to Claude 2 via Amazon Bedrock
- Claude 2 generates an answer strictly grounded in enterprise data
-
Step 4 – Response Delivery
-
-
- The answer is returned via API Gateway
- Displayed instantly on the web interface
-
Step 5 – Continuous Learning
Logs and query trends are captured in Amazon CloudWatch
- Used for:
- Prompt optimization
- Content gap analysis
- Knowledge base improvement
- logic.
Security & Governance
The solution follows AWS security best practices:
-
- IAM roles & least privilege for all services
- Encryption at rest (S3, OpenSearch) and in transit (HTTPS)
- Private VPC endpoints for Bedrock and OpenSearch
- AWS CloudTrail for full audit logging
- Amazon Guard Duty for threat detection
- No customer data used for model training (Bedrock managed guarantee)
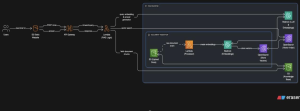
The Panoramic AI Knowledge Assistant architecture, designed and implemented by CloudStok using AWS best practices, delivers a secure, scalable, and cost-optimised Retrieval-Augmented Generation (RAG) solution for enterprise knowledge access.
Users interact with the knowledge assistant through a lightweight web or application interface exposed via Amazon API Gateway, which securely routes requests to an AWS Lambda–based orchestration layer. Lambda acts as the control plane, handling user queries, managing request flow, and coordinating interactions between the retrieval and generation components.
Enterprise documents—including SOPs, policies, process manuals, FAQs, and internal knowledge assets—are securely stored in Amazon S3, ensuring durability, versioning, and controlled access. During ingestion, documents are processed, chunked, and converted into vector embeddings using Amazon Bedrock (Titan Text Embeddings). These embeddings, along with metadata, are indexed and stored in Amazon OpenSearch Service, enabling fast and accurate semantic retrieval.
When a user submits a query, Lambda embeds the query and performs a similarity search against OpenSearch to retrieve the most relevant document context. This context is then passed to Amazon Bedrock, where Anthropic Claude Haiku generates concise, context-aware responses grounded strictly in Panoramic’s internal knowledge base—ensuring accuracy, consistency, and data isolation.
Security is enforced end-to-end using AWS IAM for fine-grained access control and AWS KMS for encryption of data at rest and in transit. Amazon CloudWatch provides continuous monitoring across API requests, Lambda execution, OpenSearch performance, and Bedrock inference latency, enabling operational visibility and proactive issue detection.
As an AWS Managed Services Partner (MSP), CloudStok delivered the complete solution lifecycle—from architecture design and service sizing to implementation and go-live. Post-deployment, CloudStok continues to provide monitoring, cost optimisation, model tuning, and platform enhancements to ensure sustained performance and business value.
Quantified Business Outcomes
- 45% reduction in time spent searching internal documents
- 35% decrease in repetitive internal support queries
- 3× faster onboarding for new employees
- >90% response accuracy through document-grounded RAG architecture
- High user adoption within the first 30 days of launch